
Overview of Lifeblood#
Lifeblood is a task management software tuned to CG industry.
Lifeblood solves the same problem as Deadline, Tractor and other farm managers, but Lifeblood does much more on top of that.
Lifeblood allows you do define task processing workflows in terms of a node graph, where tasks that travel from node to node and may produce workload to be executed by a swarm of workers.
Base concepts#
Lifeblood is a task processing system.
A short summary of how Lifeblood works is this:
task are the main entities, they carry attributes.
node define some processing logic, they are sort of like functions in programming languages.
Nodes process tasks, reading and modifying their attributes.
After task is processed, it moves to the next node, according to Node Graph.
While processing tasks, node may produce an invocation (sort of like a “closure” to be executed).
Invocation is scheduled to be executed by one of the workers.
workers may be spawned on any number of physical or virtual machines to use all available resources to process invocations.
All design concepts are explained here: Main Concepts
Main components#
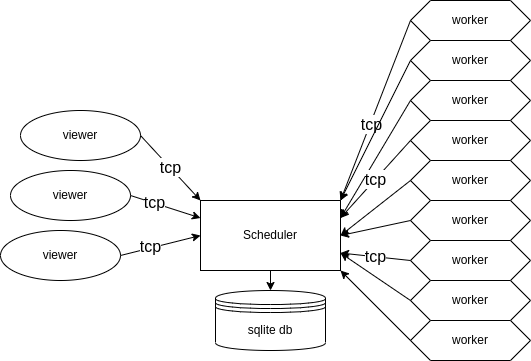
Lifeblood consists of 3 main component types:
scheduler
worker
viewer
scheduler#
Scheduler is the main brain of Lifeblood. It processes tasks, moves them around and schedules them for execution on workers.
worker#
Worker is the one component that does the (usually) heavy work specified by tasks’ invocations.
viewer#
Viewer is the tool that allows a user to view scheduler’s state. With a viewer you can see the state of the processing of your task group, or modify or create new node setups, move tasks around, or otherwise change things in scheduler.
Workers typically are managed by worker pools.
There is always one single scheduler and many workers and viewers in one setup. All the components can be launched on one or many machines within the same network.
For example:
For individual use typically it makes sense to have viewer, scheduler and a worker pool running on the same machine, with additional worker pools running on several more machines in the local network.
For a studio use probably scheduler would get it’s own dedicated machine. Worker pools would be running on farm blades, and viewers would be started by artists from their machines.
Generally, workers and viewers only need to be able to connect to scheduler, but certain types of tasks, like, for example, distributed simulation in houdini, require workers to be able to communicate to each other as well. (this requirement may be lifted in the future, if needed)
By default scheduler will start broadcasting to your default interface it’s ip and ports for any possible workers and viewers
running on the same local network - this eases the small setups as all you need to do is just to launch components and they
will find each other automatically.
You can change that behaviour in scheduler’s config. in core section broadcast = false would disable the broadcast,
with server_ip, server_port you can override ip and port to use for worker connections, and with ui_ip, ui_port
you can override ip and port to use for viewer connections.
Note
IF BROADCASTING IS OFF it is quite possible to run multiple schedulers on the same network (though you should not have a need to do it), or even on the same machine (but they MUST use different databases). But if broadcasting if enabled - multiple schedulers on the same local network will start to conflict with each other. Again: you should NOT have a need to run multiple schedulers.
Configuration#
Configuration for lifeblood components is done with config files. Config files are located by default in your user folder, see Config location
Database location#
A scheduler’s database is something like a farm manager repository - it’s where all nodes and tasks are stored.
You can have multiple databases and switch between them, but at one time only one may be used.
Read more at Database
Warning
do NOT run multiple schedulers with different databases at the same time. Though it is supported in general - it requires some configuration, like disabling broadcasting. So you need to know what you are doing
Distribution#
The components arranged into 2 packages on pypi.org:
lifeblood: scheduler and worker
lifeblood_viewer: viewer (requires lifeblood)
As you see, viewer is separated from main package to avoid GUI dependencies for scheduler and worker, and to make lifeblood package lighter.
Requirements#
python3.8 or higher is required
OS support#
There is nothing strictly os-specific, except signal handling and process managing by the worker.
Currently it was only tested in linux.
MacOS, being posix, should theoretically work without problems too. Windows requires some os-specific modifications. it should work, but was never properly tested.